


Duplicate files such as documents and photos can occupy a surprising amount of space on your Mac’s hard disk and you might not even realise they are there.
Perhaps you’ve copied files into several folders and external USB drives, and additional copies could exist in the Mail downloads folder. You might even find a few gigabytes of duplicate content in iTunes, normally because several albums from the same artist might contain the same tracks (e.g. an album and a greatest hits).
It’s therefore a good idea to get rid of those unwanted duplicates which are just clogging up your system, especially if you’re a bit low on disk space.
iTunes also has the ability to find duplicate items, which is covered later in this tutorial.

METHOD 1: Use a Third-Party Application
There are dozens of apps available in the Mac App Store which can find and remove duplicate files. Some are free whereas others charge a small fee. They all do pretty much the same thing but some have much more comprehensive features and allow you to filter by filename only or the actual content. For example, it’s possible that multiple identical files have different filenames – utilities such as those mentioned below can help to analyse the contents of files on a byte level to determine if they really are duplicates.
We have tested and found these apps to be effective, but its worth noting there are many more available on the Mac App Store:

METHOD 2: Use Finder to Locate Duplicates
Duplicate files can be found quite easily using Finder. The process is rather slow because you need to manually decide which ones to keep and which to delete, but with just a little time and patience you can locate most duplicate items.
Follow the method below:
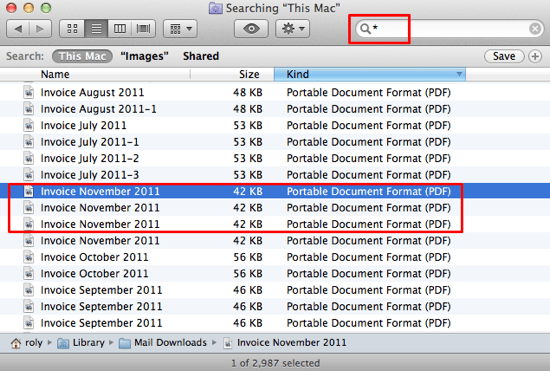
- Open a new Finder window
- In the search field, enter the wild card asterisk symbol
- Make sure the Size and Kind columns are displayed
- Filter the results by Kind, and you will see the list of similar items
This method is fairly accurate because it shows identical files listed by name, type, and size. Just delete any files that you don’t want to keep but make sure they really are duplicates first. Unfortunately, this method doesn’t let you determine whether the files are true byte-level copies but there is enough information presented to be able to make an informed decision. The main drawback with this method is the amount of time it takes to go through the items one at a time.

A Note on How to Remove Duplicate Items in iTunes
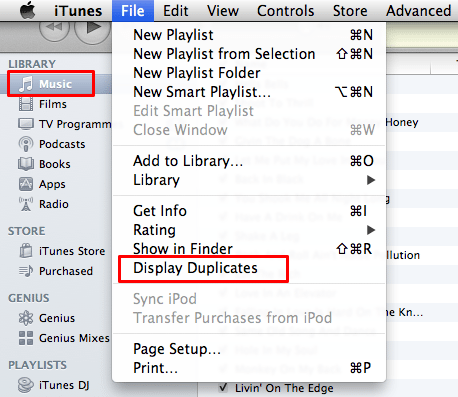
Fortunately iTunes provides the ability to check for duplicate files, as follows:
- Make sure you’ve highlighted the relevant item in your iTunes library (such as Music, Films, Podcasts, etc)
- In the File menu, select Display Duplicates
Any duplicate items found will be displayed in the main iTunes window, allowing you to simply delete them as normal.



Hold down the ALT key while selecting duplicates in iTunes to find EXACT duplicates and tracks that just match name.
Great Product, Terrible Product Name (Chipmunk??)
Thanks for the great review, Chris. After having used Remove Duplicate Items in iTunes I decided I needed a more robust application. I checked out all 5 applications reviewed above:
ACDSee Duplicate Finder
Araxis Find Duplicate Files
Chipmunk
Gemini: The Duplicate Finder.
Search Duplicate Files plus Tidy Up
I decided to go with Chipmunk and am very pleased with the result. Even tho more expensive than Gemini or Araxis it is far more robust. For example, Chipmunk found iTunes music files that had been misnamed but, were the same song, i.e., Scarlet Begonias by Grateful Dead had a duplicate mislabeled ‘Radio Head at Bank of America’ Using Chipmunk’s ‘Quick Look’ function i could play both versions and determine that they were, in fact, duplicates. This is also true for photos. I am very glad I bought Chipmunk. It is fast, easy to use and very useful at cleaning up duplicates.
Thank you!! This has been very helpful!! :))
Thank you!! This has been very helpful!! :))
Gemini no longer works. I downloaded last week (april 2013) it only allows manual deletion, and even then kept warning me about deleting the original. I got a refund and am now searching for a program that works in 2013.
Gemini no longer works. I downloaded last week (april 2013) it only allows manual deletion, and even then kept warning me about deleting the original. I got a refund and am now searching for a program that works in 2013.
iTunes doesn’t have the Find Duplicates option under the File menu on my computer. It is the latest version, and the system is 10.6.8 Any ideas if that option exists somewhere else?
Also, when trying to use the Finder search to locate duplicate items, I cannot find how to add a Size column to the menu, only to the search criteria. It must be simple, help, please. The Help lookup doesn’t, in fact, help.
iTunes doesn’t have the Find Duplicates option under the File menu on my computer. It is the latest version, and the system is 10.6.8 Any ideas if that option exists somewhere else?
Also, when trying to use the Finder search to locate duplicate items, I cannot find how to add a Size column to the menu, only to the search criteria. It must be simple, help, please. The Help lookup doesn’t, in fact, help.
it is under “VIEW” show duplicate items
Greetings, Bá
it is under “VIEW” show duplicate items
Greetings, Bá
Thanks for the information. Also try Long Path Tool. It helped me with Error 1320 on Win 7. 🙂
When it comes to duplicate file management I always use Singlemizer.
When I try this, I modified the line to remove the fancy quotes and replace them with simple ‘ quotes. Also, there is an em dash instead of a minus sign, so I changed that. Both before and after though, it errors: ‘grep: -: No such file or directory’
There’s a problem here, Chris. Mac uses the BSD grep, while the command that you’ve posted is most probably for GNU grep. The two versions of the tools are similar, but not identical.
The issue is the – following the grep command. GNU grep interprets this as stdin (thus, those lines that have been identified as duplicates by uniq -d), while BSD grep is actually looking for a file called -.
Nice article! For some reason a lot of my songs have duplicated, tripled or even quadrupled. it’s very annoying because i can’t play an album straight through. Therefore I searched on google and found a good software. It is called MUSIC CLEANUP. It is really amazing to remove all my duplicates all at once.
Ja, that command line fails for multiple reasons. The ‘fancy’ quotes and em dash are two reasons (dammit Jim, I’m a graphic designer, not a programmer). The other seems to be deprecated behaviour in grep.
Very badly, I’ll explain. Each | (bar symbol) is a pipe and joins the output from one command to another. So, explaining one command at a time:
first is a find on current directory (.) for files more than 1k (-size 20) that aren’t directories (\! (not) -type d) and execute a checksum on these files (-exec cksum {} \;). The effect is to output a list of files with their directory relative to current directory and their checksum and block count (size in 512bytes).
Next bit says take this list of files with checksums, and sort them alphabetically by the first item in the list (the checksum).
Next bit is tee which means put this output here and there, in this case put it to the file /tmp/f.tmp, and also to standard output (the screen, or in this case, pipe it along to the next command).
Next bit is cut which, when you fix the quotes, takes the first two words from our list (the checksum and size) and discards the rest (the filename)
Next bit is uniq, which because of the -d option, prints all the items occurring more than once (ie duplicates)
Next bit, and this is the grunter, is a grep which says “show me all the items in /temp/f.tmp (the original output with the file name) which match the list of duplicate checksums I have been piped” and redirect that list to duplicates.txt
That last command, grep, is a little off. The options are -hif which are:
-h : don’t print the filename (odd, as it should be off by default)
-i : ignore case (odd, since the input is just numbers – checksum and size)
-f : read from this file for our patterns to search for, which along with the following ” – ” is actually meant to mean read from standard in.
Now the exciting bit where something interesting is revealed. In OS X, Gnu grep was replaced with BSD grep in Mountain Lion (10.8). This means that this command line won’t work on 10.8+, since BSD grep does not support the “-f – ” option to read from standard in. So, what to do?
Well, the standard approach is to wrap the piped commands inside the grep using $(commands), but that would get very ugly very quickly since we have many layers. An alternative, if less attractive measure is to redirect the output from uniq -d to another file. This means breaking the command in two:
find . -size 20 \! -type d -exec cksum {} \; | sort | tee /tmp/f.tmp | cut -f 1,2 -d ‘ ‘ | uniq -d > /tmp/checksums.tmp
grep -f /temp/checksums.tmp /tmp/f.tmp > duplicates.txt
If you really want it in one line, then you can add an “&” or better “”&&” thusly:
find . -size 20 \! -type d -exec cksum {} \; | sort | tee /tmp/f.tmp | cut -f 1,2 -d ‘ ‘ | uniq -d > /tmp/checksums.tmp && grep -f /temp/checksums.tmp /tmp/f.tmp > duplicates.txt
But there’s more. For large numbers of arbitrary files, it is possible that you will have the same checksum and filesize – low chance, but still possible. In this case you might wish to use a better hashing function, MD5 or SHA. But then you run into the problem of computing large numbers of hashes. So, an alternative is to match on filesize first, and if the file size is the same, then do a hash, this reduces the number of hashes you need to do.
a sample:
find . size 20 -type f -ls | awk ‘{print $7}’ | grep -e “[0-9]\{$MINBYTES,\}$” | sort -rn | uniq -d | xargs -I{} -n1 find . -type f -size{}c -print0 | xargs -0 md5sum | sort -rn > /tmp/md5hashlist.txt ; awk ‘{print $1}’ /tmp/md5hashlist.txt | uniq -d > /tmp/dupehashes.txt ; grep -f $md5dupehashes.txt md5hashlist.txt > dupefiles.txt